



























DeepSeek的Janus-Pro表现如何?
本文来自微信公众号:王智远,作者:王智远,题图来源:AI生成昨晚,刷新闻时看到:DeepSeek创始人梁文峰已经回广州老家过年了。然而,在2025年1月27日凌晨(除夕夜)前夕,他们团队发布了一款新模型:多模态框架Janus-Pro。朋友在社群中吐槽道,估计他是想以中国人的方式,和美国AI圈一起庆祝春节。这款模型一发布,让本来就爆火的DeepSeek又一次成为了焦点。黄仁勋看了可能都想说:一晚上干掉我几千亿市值,年轻人不讲武德,下手没个轻重,居然还在除夕夜搞事情。不过,吐槽归吐槽,模型确实值得关注。我不是技术从业者,但可以把自身的理解汇报给你。一整个报告一共有四点。第一点是:DeepSeek Janus-Pro是什么?它是一款先进的多模态理解和生成模型,是之前Janus模型的升级版。简单讲,这个模型能够同时处理文本、图像,即可以理解图片内容,也能文生图。为什么叫这个名字呢?在罗马神话中,Janus(雅努斯)是象征着矛盾和过渡的双面守护神,他有两副面孔,一副看着过去,一副看着未来,象征着开始和结束。这个模型设计理念是双重的,能理解图像又能生成图像,所以,它非常贴切模型的双重能力,才叫:雅努斯。问题来了,之前有Janus,为什么还要推出PRO版?报告中提到,现在多模态模型虽然已经很厉害,但处理复杂的任务时,还有诸多不足,有些模型在理解图片内容时表现不错,但生成图片可能不稳定,要么细节处理不到位、甚至描述和想象的不一样;为了解决一系列问题,因此,才推出Janus-Pro版。既然这样,Janus-Pro版采用什么样的架构呢?官方说:整体架构的核心设计原则是,将多模态理解任务和视觉生成任务的视觉编码进行解耦;我们应用独立的编码方法将原始输入转换为特征,然后,通过统一的自回归变换器进行处理。图释:Janus-Pro模型架构示意图,如何分别处理理解图像和生成图像的任务这段话比较复杂。我举个例子:现在有个超级机器人叫Janus-Pro。它的大脑被设计成两个部分,一个负责理解图片,另一个负责根据文字描述来画画。当机器人看到一张图片时,会用一个特别的“眼睛”(叫SigLIP编码器)来仔细观察图片,然后,把看到的内容变成一串数字(高维语义特征)。这些数字像图片的“指纹”,能帮助机器人理解图片里有什么。接下来,数字会被整理成一排,通过一个翻译器(适配器)转换成机器理解的语言。当机器人需要根据文字描述画面时,它会用另一个工具(叫VQ tokenizer)把图片变成一串代码(离散ID)。这些代码,就像图片的“密码”,机器人可以根据密码重建照片。紧接着,代码也会被整理成一排,通过另一个“翻译器”(生成适配器)转换成机器人能理解的语言;最后,机器人把两部分信息(理解图片的内容和根据文字描述画画的信息)和合并在一起,通过大脑(语言模型)来处理,最后,机器就能看到你要的东西了。简单讲,有四步:理解照片、提炼成语义、转换成机器人看得懂的东西、合并成你想要的东西。这是第一部分,它是什么?它的架构什么样。二那么,它是怎么训练出来的呢?一共有三个阶段:第一阶段,专注于训练适配器和图像头部。第二阶段处理统一预训练,第三阶段,监督微调。但我认为,这样理解比较复杂。打个比方:你现在正在教一个小孩学画画。一开始,你不会直接让他画一幅复杂的风景画,而是先让他练习画简单的形状,比如圆圈、正方形。等他把基本形状画得熟练了,再逐步增加难度,让他画更复杂的东西。Janus-Pro的训练也是这样的。第一阶段,打基础。就像让小孩练习画“基本形状”一样,Janus-Pro会先专注于学习图像基本特征,比如颜色、线条等。这个阶段的训练步骤增加了,模型才有更多时间学习基本特征,如此一来,即便在固定的语言模型参数下,模型也能有效模拟像素的规律,根据类别生成合理的框架。到了第二阶段,增强难度。当小孩能够熟练画出基本形状后,就可以开始画更复杂的东西了。同样,Janus-Pro在这个阶段。会开始处理更复杂的任务,比如:根据文本描述生成图像。这个阶段的训练数据也做了优化,直接使用正常的文本到图像数据,提高了训练效率,这样,模型能够更高效地利用文本到图像数据,从而提升了整体性能。第三阶段,检验成果。就像让孩子参加画画比赛,检验他的学习成果一样,Janus-Pro在这个阶段会同时处理多模态理解任务和文本到图像生成任务,进一步优化模型的性能。比如:将多模态数据、纯文本数据和文本到图像数据的比例从7:3:10调整为5:1:4,进一步提升模态的理解能力。在数据上,官方提到:在Janus-Pro中,我们加入了大约7200万样本的合成美学数据,使得统一预训练阶段中真实数据与合成数据的比例达到1:1,这些合成数据样本的提示是公开可用的。实验证明,模型在合成数据上训练时,收敛速度更快,生成的文本到图像输出不仅更稳定,而且在审美质量上也有显著提升。说白了,我认为,这三个步骤,如果总结归纳的话,用中国话叫:比着葫芦画瓢。问题来了:光画不够,因为,小朋友想画出一幅好画,必须要学很多东西,去理解世界,看各种各样的动物、照片,才有抽象的能力。怎么办?为了提高Janus-Pro在任务中的表现,团队增加了大量的图像字幕数据、表格图表、以及文档理解数据;这些数据,能让模型有机会学习不同的东西。这叫:多模态理解数据的能力。然后,团队又增加了大量的合成美学数据。这些数据让模型,有更多机会学习如何生成高质量的图像,从而提高模型的生成能力。因此,“比着葫芦画瓢连”加上学习,它才能在日常中更出色。三可是,光有数据和学习能力还不够,就像小朋友要长大,需要不断提升认知能力一样,Janus-Pro也要“长大”。那么,它是怎么“长大”的呢?官方提到,先前版本使用的是1.5B语言模型,验证了视觉编码解耦的有效性。而在Janus-Pro中,团队将模型扩展到了7B,并对1.5B和7B语言模型的超参数进行了优化。具体来说,1.5B模型的嵌入大小为2048,上下文窗口为4096,注意力头数为16,层数为24。而7B模型的嵌入大小为4096,上下文窗口为4096,注意力头数为32,层数为30。看到这些数字,你可能会觉得头大。其实,参数可以抽象地理解为模型“大脑”的升级:嵌入大小:就像模型“记忆容量”,越大,能记住的信息就越多上下文窗口:就像模型“视野范围”,越大,能看到的上下文信息就越丰富注意力头数:就像模型“注意力焦点”,越多,能同时关注的细节就越多层数:就像模型的“思考深度”,越多,能进行的思考就越复杂通过升级,Janus-Pro的“大脑”从一个小学生变成了一个大学生,能力得到了全面提升。官方团队发现,使用更大规模的语言模型时,多模态理解和视觉生成的损失收敛速度,显著提高,与较小模型相比,性能提升明显。这一发现,进一步验证了这种方法的强大可扩展性。说白了,更大模型就像一支更高级的画笔,能够更精细地处理复杂的任务,生成更高质量的图像和更准确的理解结果。图释:Janus-Pro模型超参数配置概览那么,这些升级如何实现呢?来看看训练过程。官方提到:Janus-Pro使用了DeepSeek-LLM作为基础语言模型,这是一个支持最大序列长度为4096的强大模型。对于视觉编码器,Janus-Pro选择了SigLIP-Large-Patch16-384,这是一个能够从图像中提取高维语义特征的编码器。生成编码器的码本大小为16,384,图像下采样因子为16。训练过程中,Janus-Pro采用了多种优化策略;例如,使用了AdamW优化器,使得学习率在不同阶段逐渐调整。整个训练过程在HAI-LLM框架上进行,强大的硬件支持确保,Janus-Pro能够在短时间内完成复杂的训练任务。这些数据看不懂没关系,我抽象解释下:你家小孩要参加一个画画比赛,你需要为他准备一套好用的画具,还得找一位经验丰富的老师来指导他,对吧?DeepSeek-LLM像那套高级画具,能够帮助Janus-Pro更好地处理复杂的任务。AdamW优化器,像经验丰富的老师,会根据小孩的学习进度,逐渐调整教学难度,让小孩在每个阶段都能稳步进步。HAI-LLM框架就像是一个宽敞明亮的画室,为小孩提供了专注创作的环境。有了软硬兼施的整体支持,Janus-Pro才能轻松应对复杂的文本描述,生成高质量的图像的任务。四理论固然重要,实际表现才是检验模型能力的真正标准,有句中国话叫什么:是骡子是马,拉出来遛遛。那么,Janus-Pro的实际表现如何呢?来看看它的评估设置和与最新技术的比较。为了验证Janus-Pro的性能,团队进行了严格的评估,他们选择了多个基准测试,包括多模态理解任务和视觉生成任务。多模态理解任务:包括GQA、POPE、MME等。这些测试就像是让Janus-Pro看一幅画,然后描述画里的内容,看看它能不能准确地理解。视觉生成任务:包括GenEval和DPG-Bench。这些测试则是给Janus-Pro一个文字描述,让它根据描述画出一幅画,看看它能不能画得像、画得好。说白了,就是反复进行“看图说话”和“说话想象图片”的双重测试。那么,Janus-Pro在这场“考试”中表现如何呢?我们可以拿它和其他的“考生”,也就是其他多模态模型——来做比较。首先,多模态理解任务上:Janus-Pro在MMBench基准测试中得分79.2,超过了其他一些知名的模型,比如TokenFlow-XL(68.9)和MetaMorph(75.2)。这像在一场画画比赛中,Janus-Pro的画作得到更高的评价,说明它在理解图像内容方面确实很厉害。对了,TokenFlow-XL是ByteFlow-AI团队开发的一个多模态模型,而MMBench由Meta公司开发;这两个对比充分说明了Janus-Pro在多模态理解任务中的领先地位。图释:多模态理解基准测试中不同模型性能对比其次,在视觉生成任务上:Janus-Pro在GenEval基准测试中的得分(0.80),也超过了DALL-E 3(0.67)和Stable Diffusion 3 Medium(0.74)等模型。这像给Janus-Pro一个文字描述,让它画出一幅画,结果它画得比其他模型更准确、更细致,说明它在根据文字描述生成图像方面也很出色。对了,DALL-E 3是OpenAI开发的文生图模型,而 Stable Diffusion 3 Medium不用说了,众所周知,专注于生成高质量图片,特别在中等分辨率下表现出色。所以,结论是什么?一句话总结即:Janus-Pro在这场“考试”中表现优异,吊打部分行业头部模型。还有一点是:这些测试不是自己测的。是专业机构gemimi和DPG bench权威认证,在hanggenface开源官网更新。报告参考:[1].发布地址:https://huggingface.co/deepseek-ai/Janus-Pro-1B[2].报告地址:https://github.com/deepseek-ai/Janus/blob/main/janus_pro_tech_report.pdf
本文来自微信公众号:王智远,作者:王智远,题图来源:AI生成
昨晚,刷新闻时看到:
DeepSeek创始人梁文峰已经回广州老家过年了。然而,在2025年1月27日凌晨(除夕夜)前夕,他们团队发布了一款新模型:多模态框架Janus-Pro。
朋友在社群中吐槽道,估计他是想以中国人的方式,和美国AI圈一起庆祝春节。
这款模型一发布,让本来就爆火的DeepSeek又一次成为了焦点。黄仁勋看了可能都想说:一晚上干掉我几千亿市值,年轻人不讲武德,下手没个轻重,居然还在除夕夜搞事情。
不过,吐槽归吐槽,模型确实值得关注。我不是技术从业者,但可以把自身的理解汇报给你。
一
整个报告一共有四点。第一点是:DeepSeek Janus-Pro是什么?
它是一款先进的多模态理解和生成模型,是之前Janus模型的升级版。简单讲,这个模型能够同时处理文本、图像,即可以理解图片内容,也能文生图。
为什么叫这个名字呢?
在罗马神话中,Janus(雅努斯)是象征着矛盾和过渡的双面守护神,他有两副面孔,一副看着过去,一副看着未来,象征着开始和结束。
这个模型设计理念是双重的,能理解图像又能生成图像,所以,它非常贴切模型的双重能力,才叫:雅努斯。
问题来了,之前有Janus,为什么还要推出PRO版?
报告中提到,现在多模态模型虽然已经很厉害,但处理复杂的任务时,还有诸多不足,有些模型在理解图片内容时表现不错,但生成图片可能不稳定,要么细节处理不到位、甚至描述和想象的不一样;为了解决一系列问题,因此,才推出Janus-Pro版。
既然这样,Janus-Pro版采用什么样的架构呢?
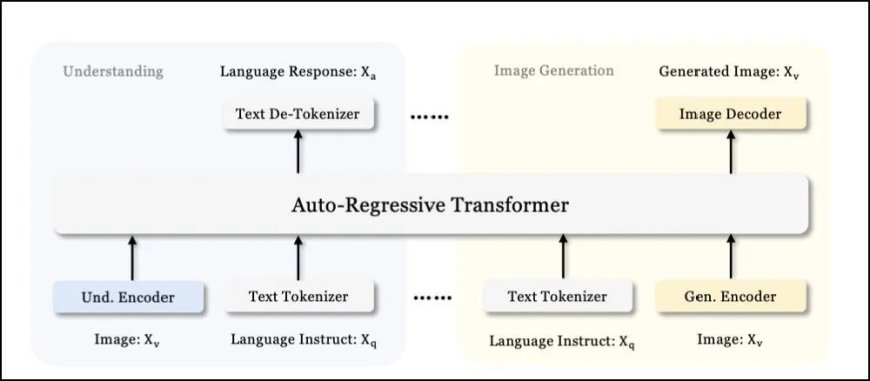
官方说:整体架构的核心设计原则是,将多模态理解任务和视觉生成任务的视觉编码进行解耦;我们应用独立的编码方法将原始输入转换为特征,然后,通过统一的自回归变换器进行处理。

图释:Janus-Pro模型架构示意图,如何分别处理理解图像和生成图像的任务
这段话比较复杂。我举个例子:
现在有个超级机器人叫Janus-Pro。它的大脑被设计成两个部分,一个负责理解图片,另一个负责根据文字描述来画画。
当机器人看到一张图片时,会用一个特别的“眼睛”(叫SigLIP编码器)来仔细观察图片,然后,把看到的内容变成一串数字(高维语义特征)。
这些数字像图片的“指纹”,能帮助机器人理解图片里有什么。接下来,数字会被整理成一排,通过一个翻译器(适配器)转换成机器理解的语言。
当机器人需要根据文字描述画面时,它会用另一个工具(叫VQ tokenizer)把图片变成一串代码(离散ID)。这些代码,就像图片的“密码”,机器人可以根据密码重建照片。
紧接着,代码也会被整理成一排,通过另一个“翻译器”(生成适配器)转换成机器人能理解的语言;最后,机器人把两部分信息(理解图片的内容和根据文字描述画画的信息)和合并在一起,通过大脑(语言模型)来处理,最后,机器就能看到你要的东西了。
简单讲,有四步:理解照片、提炼成语义、转换成机器人看得懂的东西、合并成你想要的东西。这是第一部分,它是什么?它的架构什么样。
二
那么,它是怎么训练出来的呢?一共有三个阶段:
第一阶段,专注于训练适配器和图像头部。第二阶段处理统一预训练,第三阶段,监督微调。但我认为,这样理解比较复杂。
打个比方:
你现在正在教一个小孩学画画。一开始,你不会直接让他画一幅复杂的风景画,而是先让他练习画简单的形状,比如圆圈、正方形。等他把基本形状画得熟练了,再逐步增加难度,让他画更复杂的东西。Janus-Pro的训练也是这样的。
第一阶段,打基础。就像让小孩练习画“基本形状”一样,Janus-Pro会先专注于学习图像基本特征,比如颜色、线条等。
这个阶段的训练步骤增加了,模型才有更多时间学习基本特征,如此一来,即便在固定的语言模型参数下,模型也能有效模拟像素的规律,根据类别生成合理的框架。
到了第二阶段,增强难度。
当小孩能够熟练画出基本形状后,就可以开始画更复杂的东西了。同样,Janus-Pro在这个阶段。会开始处理更复杂的任务,比如:根据文本描述生成图像。
这个阶段的训练数据也做了优化,直接使用正常的文本到图像数据,提高了训练效率,这样,模型能够更高效地利用文本到图像数据,从而提升了整体性能。
第三阶段,检验成果。
就像让孩子参加画画比赛,检验他的学习成果一样,Janus-Pro在这个阶段会同时处理多模态理解任务和文本到图像生成任务,进一步优化模型的性能。
比如:将多模态数据、纯文本数据和文本到图像数据的比例从7:3:10调整为5:1:4,进一步提升模态的理解能力。
在数据上,官方提到:
在Janus-Pro中,我们加入了大约7200万样本的合成美学数据,使得统一预训练阶段中真实数据与合成数据的比例达到1:1,这些合成数据样本的提示是公开可用的。
实验证明,模型在合成数据上训练时,收敛速度更快,生成的文本到图像输出不仅更稳定,而且在审美质量上也有显著提升。
说白了,我认为,这三个步骤,如果总结归纳的话,用中国话叫:比着葫芦画瓢。
问题来了:光画不够,因为,小朋友想画出一幅好画,必须要学很多东西,去理解世界,看各种各样的动物、照片,才有抽象的能力。
怎么办?
为了提高Janus-Pro在任务中的表现,团队增加了大量的图像字幕数据、表格图表、以及文档理解数据;这些数据,能让模型有机会学习不同的东西。这叫:多模态理解数据的能力。
然后,团队又增加了大量的合成美学数据。这些数据让模型,有更多机会学习如何生成高质量的图像,从而提高模型的生成能力。
因此,“比着葫芦画瓢连”加上学习,它才能在日常中更出色。
三
可是,光有数据和学习能力还不够,就像小朋友要长大,需要不断提升认知能力一样,Janus-Pro也要“长大”。那么,它是怎么“长大”的呢?
官方提到,先前版本使用的是1.5B语言模型,验证了视觉编码解耦的有效性。而在Janus-Pro中,团队将模型扩展到了7B,并对1.5B和7B语言模型的超参数进行了优化。
具体来说,1.5B模型的嵌入大小为2048,上下文窗口为4096,注意力头数为16,层数为24。而7B模型的嵌入大小为4096,上下文窗口为4096,注意力头数为32,层数为30。
看到这些数字,你可能会觉得头大。其实,参数可以抽象地理解为模型“大脑”的升级:
嵌入大小:就像模型“记忆容量”,越大,能记住的信息就越多
上下文窗口:就像模型“视野范围”,越大,能看到的上下文信息就越丰富
注意力头数:就像模型“注意力焦点”,越多,能同时关注的细节就越多
层数:就像模型的“思考深度”,越多,能进行的思考就越复杂
通过升级,Janus-Pro的“大脑”从一个小学生变成了一个大学生,能力得到了全面提升。
官方团队发现,使用更大规模的语言模型时,多模态理解和视觉生成的损失收敛速度,显著提高,与较小模型相比,性能提升明显。这一发现,进一步验证了这种方法的强大可扩展性。
说白了,更大模型就像一支更高级的画笔,能够更精细地处理复杂的任务,生成更高质量的图像和更准确的理解结果。

图释:Janus-Pro模型超参数配置概览
那么,这些升级如何实现呢?来看看训练过程。
官方提到:
Janus-Pro使用了DeepSeek-LLM作为基础语言模型,这是一个支持最大序列长度为4096的强大模型。
对于视觉编码器,Janus-Pro选择了SigLIP-Large-Patch16-384,这是一个能够从图像中提取高维语义特征的编码器。生成编码器的码本大小为16,384,图像下采样因子为16。
训练过程中,Janus-Pro采用了多种优化策略;例如,使用了AdamW优化器,使得学习率在不同阶段逐渐调整。整个训练过程在HAI-LLM框架上进行,强大的硬件支持确保,Janus-Pro能够在短时间内完成复杂的训练任务。
这些数据看不懂没关系,我抽象解释下:
你家小孩要参加一个画画比赛,你需要为他准备一套好用的画具,还得找一位经验丰富的老师来指导他,对吧?
DeepSeek-LLM像那套高级画具,能够帮助Janus-Pro更好地处理复杂的任务。
AdamW优化器,像经验丰富的老师,会根据小孩的学习进度,逐渐调整教学难度,让小孩在每个阶段都能稳步进步。HAI-LLM框架就像是一个宽敞明亮的画室,为小孩提供了专注创作的环境。
有了软硬兼施的整体支持,Janus-Pro才能轻松应对复杂的文本描述,生成高质量的图像的任务。
四
理论固然重要,实际表现才是检验模型能力的真正标准,有句中国话叫什么:是骡子是马,拉出来遛遛。那么,Janus-Pro的实际表现如何呢?
来看看它的评估设置和与最新技术的比较。为了验证Janus-Pro的性能,团队进行了严格的评估,他们选择了多个基准测试,包括多模态理解任务和视觉生成任务。
多模态理解任务:包括GQA、POPE、MME等。这些测试就像是让Janus-Pro看一幅画,然后描述画里的内容,看看它能不能准确地理解。
视觉生成任务:包括GenEval和DPG-Bench。这些测试则是给Janus-Pro一个文字描述,让它根据描述画出一幅画,看看它能不能画得像、画得好。
说白了,就是反复进行“看图说话”和“说话想象图片”的双重测试。
那么,Janus-Pro在这场“考试”中表现如何呢?我们可以拿它和其他的“考生”,也就是其他多模态模型——来做比较。
首先,多模态理解任务上:
Janus-Pro在MMBench基准测试中得分79.2,超过了其他一些知名的模型,比如TokenFlow-XL(68.9)和MetaMorph(75.2)。这像在一场画画比赛中,Janus-Pro的画作得到更高的评价,说明它在理解图像内容方面确实很厉害。
对了,TokenFlow-XL是ByteFlow-AI团队开发的一个多模态模型,而MMBench由Meta公司开发;这两个对比充分说明了Janus-Pro在多模态理解任务中的领先地位。

图释:多模态理解基准测试中不同模型性能对比
其次,在视觉生成任务上:
Janus-Pro在GenEval基准测试中的得分(0.80),也超过了DALL-E 3(0.67)和Stable Diffusion 3 Medium(0.74)等模型。
这像给Janus-Pro一个文字描述,让它画出一幅画,结果它画得比其他模型更准确、更细致,说明它在根据文字描述生成图像方面也很出色。
对了,DALL-E 3是OpenAI开发的文生图模型,而 Stable Diffusion 3 Medium不用说了,众所周知,专注于生成高质量图片,特别在中等分辨率下表现出色。
所以,结论是什么?
一句话总结即:Janus-Pro在这场“考试”中表现优异,吊打部分行业头部模型。还有一点是:这些测试不是自己测的。是专业机构gemimi和DPG bench权威认证,在hanggenface开源官网更新。
报告参考:
[1].发布地址:https://huggingface.co/deepseek-ai/Janus-Pro-1B
[2].报告地址:https://github.com/deepseek-ai/Janus/blob/main/janus_pro_tech_report.pdf












