



























DeepSeek“破圈”背后,“回声一代”刷新中国科创范式
【文/观察者网 心智观察所】 请思考,以下两家公司,哪一家更值得投资: 1.全息电视制造商,宣称将彻底颠覆电视机乃至内容生产业态; 2.传统电视制造商,计划依托新技术提升现有产品性价比; 这道商业思维例题,出自肯尼斯·斯坦利(Kenneth Stanley)和乔·雷曼(Joel Lehman)合著的畅销书《为什么伟大不能被计划》。书中,两位前OpenAI技术专家反复强调这样一个反直觉的论点:过于宏伟的目标往往是成功的绊脚石,利用现实技术机会自由探索,反而可能开启伟大创新之路。 他们恐怕不会想到,启发其新思维的OpenAI,有朝一日却会摆足架势“计划伟大”。 1月21日,OpenAI正式官宣星际之门(Stargate)项目,计划未来四年内斥资5000亿美元,在美国本土建设新的人工智能基础设施,该基础设施将“确保美国在人工智能领域的领导地位,创造数十万个美国就业机会,并为全世界带来巨大的经济效益……这一新举措是这条道路(实现AGI)上的关键一步,将使富有创造力的人能够弄清楚如何利用人工智能来提升人类”。 讽刺的是,OpenAI造势已久的万亿大计,全然没有激起预计的热烈反响。 过去一周,在美国力压OpenAI热度的,赫然是一家来自中国的小公司—深度求索(DeepSeek)。 任务表现一步追平4o/o1、训推效率断崖式领先、没有千奇百怪的DEI禁忌“对齐”……一个又一个“绝活”,令杨立昆(Yann LeCun)、卡帕西(Andrej Karpathy)等业界领军人物纷纷变身迷弟,对DeepSeek V3\R1不吝肉麻吹捧,“OpenAI原本该成为的样子”(Mistral AI曾享有的评价)、“开源大模型全球创新中心已转移至中国”、“重构大模型商业模式”,更有甚者,在硅谷创投教父马克·安德森(Marc Andreessen)看来,DeepSeek-R1已堪与特朗普入主白宫并列,成为本世纪20年代最重要一周的两大里程碑事件。 的确,无论从中国产业界“奋起直追OpenAI”的主体视角,还是从美国产业高地开源闭源之争的他者视角,横空出世的DeepSeek,都已被引为终结议题、开启新章的标志,注定将在波澜壮阔的人工智能新浪潮里,留下自己不可磨灭的印记。 当OpenAI已踌躇满志开始大手笔塑造产业生态终局,当谷歌、Anthropic、xAI、Meta等硅谷巨头还在为坐稳老二的位置苦苦厮杀,当国内大厂在“比OpenAI落后多久”的问题上继续打磨着阿基里斯悖论式的话术,DeepSeek为什么能够成为缔造这场开年“技术惊奇”的主角? 过硬的原始创新能力,当然是最直接的答案。 如果说DeepSeekMoE、FP8数据格式和RL后训练范式尚且还有着一目了然的借鉴脉络,那么MLA和GRPO,则无疑已展现出独到精妙的洞察,足以成为新范式的开创者。 以创造大模型成本奇迹的MLA(Multi-head Latent Attention)技术为例,其核心灵感可以归结为有意用更多的计算量换取更小的KV Cache,进而缓解模型训练中更为根本的访存瓶颈。这种对多头注意力机制大刀阔斧的深度改造,足以证明DeepSeek团队算法与工程基因的深度交融,从而大有别于对TensorFlow或PyTorch底层技术实现机制毫无兴趣的所谓“算法工程师”,获得全局优化的新视角。 然而与某种或许会顺理成章被唤起的想象不同,DeepSeek这支团队相比其他国内大厂和“小龙”,用“寒酸”和“土气”来形容也不为过。论资金投入,母公司幻方量化的研发预算加上“每年几个亿”可供机动的捐款,与某几家国内头部大厂相比有着一到两个数量级的悬殊差距;论人才储备,与动辄清北博士打底,硅谷回国专家领衔的豪华阵容相比,DeepSeek团队在V2模型之前甚至没有一个“海归”,创始人梁文锋坦言,团队“并没有什么高深莫测的奇才,都是一些Top高校的应届毕业生、没毕业的博四、博五实习生,还有一些毕业才几年的年轻人”。 以MLA核心贡献者高华佐为例,其最高学历“仅仅”是北大本科,2017年毕业后辗转旷视科技等多家国内“中小厂”,如果没有DeepSeek横空出世,这样的人才画像在中国可以说成千上万。 因此,在产品与技术之上,一个更有意义的追问或许是,为什么DeepSeek能够凭借算不上出挑的资金和人才储备,迸发如此强烈的“化学反应”? 创始人梁文锋所注入的“企业家精神”,无疑是一个至关重要的变量。 梁文峰参加总理座谈会 以幻方投资所切入的基本面量化策略研究为起点,从2015年的百卡集群、2019年的千卡集群,到当下的万卡集群,梁文锋的自我驱动力并非来自商业上的理由,正如其在有限的两次专访中所坦言:“幻方的主要班底里,很多人是做人工智能的。当时我们尝试了很多场景,最终切入了足够复杂的金融,而通用人工智能可能是下一个最难的事之一,所以对我们来说,这是一个怎么做的问题,而不是为什么做的问题……如果一定要找一个商业上的理由,它可能是找不到的,因为划不来。从商业角度来讲,基础研究就是投入回报比很低的。OpenAI早期投资人投钱时,想的一定不是我要拿回多少回报,而是真的想做这个事……很多人会以为这里边有一个不为人知的商业逻辑,但其实,主要是好奇心驱动……对AI能力边界的好奇”。 这种超脱于商业结果的热情或者说品味,也体现在他对DeepSeek技术团队的招募和管理,梁文锋谈到,自己选人的标准“一直都是热爱和好奇心……很多人对做研究的渴望,远超对钱的在意”,对这些气味相投的“技术宅”,梁文锋也给予了充分的信任,以身作则塑造了一整套独特的组织文化,“DeepSeek也全是自下而上。而且我们一般不前置分工,而是自然分工。每个人有自己独特的成长经历,都是自带想法的,不需要push他。探索过程中,他遇到问题,自己就会拉人讨论。不过当一个idea显示出潜力,我们也会自上而下地去调配资源……我们每个人对于卡和人的调动是不设上限的。如果有想法,每个人随时可以调用训练集群的卡无需审批。同时因为不存在层级和跨部门,也可以灵活调用所有人,只要对方也有兴趣……交给他重要的事,并且不干预他。让他自己想办法,自己发挥……我们的总结是,创新需要尽可能少的干预和管理,让每个人有自由发挥的空间和试错机会。创新往往都是自己产生的,不是刻意安排的,更不是教出来的”。 相比之下,绝大多数中国大模型从业者,在这一轮人工智能新浪潮里的“姿势”,还或多或少带着旧日的惯性,在短期商业目标和组织内不同层级利益取向的交互下,往往殊途同归收敛为同一种行为模式:基于开源模型和公开文献快速复刻欧美原始创新,在底层技术拿来主义的基础上,将主要精力聚焦于应用端尽快取得商业结果。恰如梁文锋所辛辣点评的:“过去很多年,中国公司习惯了别人做技术创新,我们拿过来做应用变现,但这并非是一种理所当然……我们认为随着经济发展,中国也要逐步成为贡献者,而不是一直搭便车。过去三十多年IT浪潮里,我们基本没有参与到真正的技术创新里。我们已经习惯摩尔定律从天而降,躺在家里18个月就会出来更好的硬件和软件。Scaling Law也在被如此对待。” 好在,后浪奔涌。 梁文锋的彻底与纯粹,以及这种新声音在舆论场上更强的反响,正是80后“回声一代”企业家崛起的缩影。 如果读者稍加回想,不难发现这样一个显见的趋势:梁文锋、冯骥等新一代创业者,在思维与表达上,都有着与上一代“92派”企业家截然不同的格调,而有趣的是,他们也都是出生于1981到1990年的新中国第三次人口增长高峰,或者说,属于“回声婴儿潮”世代。 细看这一代企业家,如果说黄峥、张一鸣、许仰天等先行者还自觉或不自觉的因循着上一代企业家对中国与世界的观念,那么梁文锋、冯骥等后来者,则表现出明显更强的表达欲,这背后,是对外部世界从仰视到平视的深刻变化。 马克安德森的评语,恰是与美国赢学叙事的两次冲击,正如拜登团队所营造的自由主义国际同盟势头,已如同一张画纸般被特朗普轻易戳破,让美国再次伟大所需要的是形似还是神似,特朗普显然已摩拳擦掌选择后者,而作为美利坚赢学在过去数年着力经营的标志,美国朝野为呵护其原始创新能力道成肉身的OpenAI可谓不遗余力,但DeepSeek同样让这重重高墙一夜之间变得形同鸡肋。 为兴趣而活,“不务正业”,脱离了肉体生存焦虑的回声一代后来者们,在中国商界的地平线上正批量涌现,机器人、跑车、超音速飞机,他们正重写中国创新范式,这一亿多在各行各业走向社会中坚的人群里,一定还会涌现更多、更精彩的创新故事。 最后,梁文锋的一句展望恰可作结:“以后硬核创新会越来越多。现在可能还不容易被理解,是因为整个社会群体需要被事实教育。当这个社会让硬核创新的人功成名就,群体性想法就会改变。我们只是还需要一堆事实和一个过程”。 这一堆事实的展现,已在加速。 本文系观察者网独家稿件,文章内容纯属作者个人观点,不代表平台观点,未经授权,不得转载,否则将追究法律责任。关注观察者网微信guanchacn,每日阅读趣味文章。
【文/观察者网 心智观察所】
请思考,以下两家公司,哪一家更值得投资:
1.全息电视制造商,宣称将彻底颠覆电视机乃至内容生产业态;
2.传统电视制造商,计划依托新技术提升现有产品性价比;
这道商业思维例题,出自肯尼斯·斯坦利(Kenneth Stanley)和乔·雷曼(Joel Lehman)合著的畅销书《为什么伟大不能被计划》。书中,两位前OpenAI技术专家反复强调这样一个反直觉的论点:过于宏伟的目标往往是成功的绊脚石,利用现实技术机会自由探索,反而可能开启伟大创新之路。
他们恐怕不会想到,启发其新思维的OpenAI,有朝一日却会摆足架势“计划伟大”。
1月21日,OpenAI正式官宣星际之门(Stargate)项目,计划未来四年内斥资5000亿美元,在美国本土建设新的人工智能基础设施,该基础设施将“确保美国在人工智能领域的领导地位,创造数十万个美国就业机会,并为全世界带来巨大的经济效益……这一新举措是这条道路(实现AGI)上的关键一步,将使富有创造力的人能够弄清楚如何利用人工智能来提升人类”。
讽刺的是,OpenAI造势已久的万亿大计,全然没有激起预计的热烈反响。
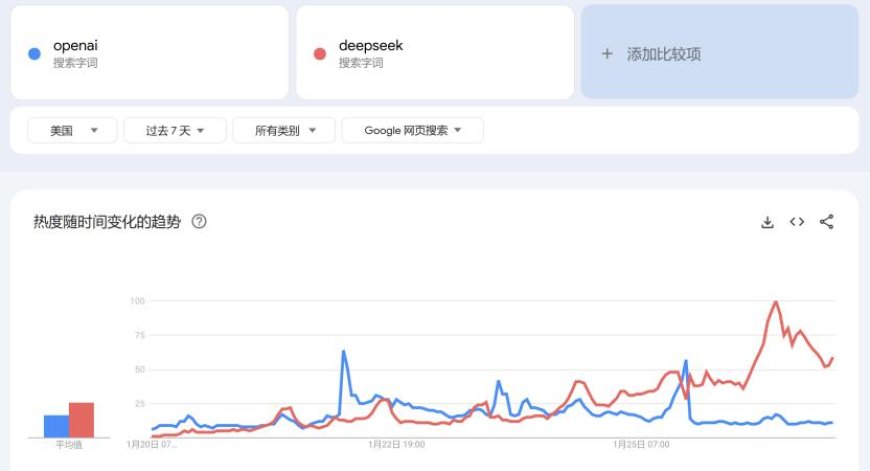
过去一周,在美国力压OpenAI热度的,赫然是一家来自中国的小公司—深度求索(DeepSeek)。

任务表现一步追平4o/o1、训推效率断崖式领先、没有千奇百怪的DEI禁忌“对齐”……一个又一个“绝活”,令杨立昆(Yann LeCun)、卡帕西(Andrej Karpathy)等业界领军人物纷纷变身迷弟,对DeepSeek V3\R1不吝肉麻吹捧,“OpenAI原本该成为的样子”(Mistral AI曾享有的评价)、“开源大模型全球创新中心已转移至中国”、“重构大模型商业模式”,更有甚者,在硅谷创投教父马克·安德森(Marc Andreessen)看来,DeepSeek-R1已堪与特朗普入主白宫并列,成为本世纪20年代最重要一周的两大里程碑事件。

的确,无论从中国产业界“奋起直追OpenAI”的主体视角,还是从美国产业高地开源闭源之争的他者视角,横空出世的DeepSeek,都已被引为终结议题、开启新章的标志,注定将在波澜壮阔的人工智能新浪潮里,留下自己不可磨灭的印记。
当OpenAI已踌躇满志开始大手笔塑造产业生态终局,当谷歌、Anthropic、xAI、Meta等硅谷巨头还在为坐稳老二的位置苦苦厮杀,当国内大厂在“比OpenAI落后多久”的问题上继续打磨着阿基里斯悖论式的话术,DeepSeek为什么能够成为缔造这场开年“技术惊奇”的主角?
过硬的原始创新能力,当然是最直接的答案。
如果说DeepSeekMoE、FP8数据格式和RL后训练范式尚且还有着一目了然的借鉴脉络,那么MLA和GRPO,则无疑已展现出独到精妙的洞察,足以成为新范式的开创者。
以创造大模型成本奇迹的MLA(Multi-head Latent Attention)技术为例,其核心灵感可以归结为有意用更多的计算量换取更小的KV Cache,进而缓解模型训练中更为根本的访存瓶颈。这种对多头注意力机制大刀阔斧的深度改造,足以证明DeepSeek团队算法与工程基因的深度交融,从而大有别于对TensorFlow或PyTorch底层技术实现机制毫无兴趣的所谓“算法工程师”,获得全局优化的新视角。
然而与某种或许会顺理成章被唤起的想象不同,DeepSeek这支团队相比其他国内大厂和“小龙”,用“寒酸”和“土气”来形容也不为过。论资金投入,母公司幻方量化的研发预算加上“每年几个亿”可供机动的捐款,与某几家国内头部大厂相比有着一到两个数量级的悬殊差距;论人才储备,与动辄清北博士打底,硅谷回国专家领衔的豪华阵容相比,DeepSeek团队在V2模型之前甚至没有一个“海归”,创始人梁文锋坦言,团队“并没有什么高深莫测的奇才,都是一些Top高校的应届毕业生、没毕业的博四、博五实习生,还有一些毕业才几年的年轻人”。
以MLA核心贡献者高华佐为例,其最高学历“仅仅”是北大本科,2017年毕业后辗转旷视科技等多家国内“中小厂”,如果没有DeepSeek横空出世,这样的人才画像在中国可以说成千上万。
因此,在产品与技术之上,一个更有意义的追问或许是,为什么DeepSeek能够凭借算不上出挑的资金和人才储备,迸发如此强烈的“化学反应”?
创始人梁文锋所注入的“企业家精神”,无疑是一个至关重要的变量。

梁文峰参加总理座谈会
以幻方投资所切入的基本面量化策略研究为起点,从2015年的百卡集群、2019年的千卡集群,到当下的万卡集群,梁文锋的自我驱动力并非来自商业上的理由,正如其在有限的两次专访中所坦言:“幻方的主要班底里,很多人是做人工智能的。当时我们尝试了很多场景,最终切入了足够复杂的金融,而通用人工智能可能是下一个最难的事之一,所以对我们来说,这是一个怎么做的问题,而不是为什么做的问题……如果一定要找一个商业上的理由,它可能是找不到的,因为划不来。从商业角度来讲,基础研究就是投入回报比很低的。OpenAI早期投资人投钱时,想的一定不是我要拿回多少回报,而是真的想做这个事……很多人会以为这里边有一个不为人知的商业逻辑,但其实,主要是好奇心驱动……对AI能力边界的好奇”。
这种超脱于商业结果的热情或者说品味,也体现在他对DeepSeek技术团队的招募和管理,梁文锋谈到,自己选人的标准“一直都是热爱和好奇心……很多人对做研究的渴望,远超对钱的在意”,对这些气味相投的“技术宅”,梁文锋也给予了充分的信任,以身作则塑造了一整套独特的组织文化,“DeepSeek也全是自下而上。而且我们一般不前置分工,而是自然分工。每个人有自己独特的成长经历,都是自带想法的,不需要push他。探索过程中,他遇到问题,自己就会拉人讨论。不过当一个idea显示出潜力,我们也会自上而下地去调配资源……我们每个人对于卡和人的调动是不设上限的。如果有想法,每个人随时可以调用训练集群的卡无需审批。同时因为不存在层级和跨部门,也可以灵活调用所有人,只要对方也有兴趣……交给他重要的事,并且不干预他。让他自己想办法,自己发挥……我们的总结是,创新需要尽可能少的干预和管理,让每个人有自由发挥的空间和试错机会。创新往往都是自己产生的,不是刻意安排的,更不是教出来的”。
相比之下,绝大多数中国大模型从业者,在这一轮人工智能新浪潮里的“姿势”,还或多或少带着旧日的惯性,在短期商业目标和组织内不同层级利益取向的交互下,往往殊途同归收敛为同一种行为模式:基于开源模型和公开文献快速复刻欧美原始创新,在底层技术拿来主义的基础上,将主要精力聚焦于应用端尽快取得商业结果。恰如梁文锋所辛辣点评的:“过去很多年,中国公司习惯了别人做技术创新,我们拿过来做应用变现,但这并非是一种理所当然……我们认为随着经济发展,中国也要逐步成为贡献者,而不是一直搭便车。过去三十多年IT浪潮里,我们基本没有参与到真正的技术创新里。我们已经习惯摩尔定律从天而降,躺在家里18个月就会出来更好的硬件和软件。Scaling Law也在被如此对待。”
好在,后浪奔涌。
梁文锋的彻底与纯粹,以及这种新声音在舆论场上更强的反响,正是80后“回声一代”企业家崛起的缩影。
如果读者稍加回想,不难发现这样一个显见的趋势:梁文锋、冯骥等新一代创业者,在思维与表达上,都有着与上一代“92派”企业家截然不同的格调,而有趣的是,他们也都是出生于1981到1990年的新中国第三次人口增长高峰,或者说,属于“回声婴儿潮”世代。
细看这一代企业家,如果说黄峥、张一鸣、许仰天等先行者还自觉或不自觉的因循着上一代企业家对中国与世界的观念,那么梁文锋、冯骥等后来者,则表现出明显更强的表达欲,这背后,是对外部世界从仰视到平视的深刻变化。
马克安德森的评语,恰是与美国赢学叙事的两次冲击,正如拜登团队所营造的自由主义国际同盟势头,已如同一张画纸般被特朗普轻易戳破,让美国再次伟大所需要的是形似还是神似,特朗普显然已摩拳擦掌选择后者,而作为美利坚赢学在过去数年着力经营的标志,美国朝野为呵护其原始创新能力道成肉身的OpenAI可谓不遗余力,但DeepSeek同样让这重重高墙一夜之间变得形同鸡肋。
为兴趣而活,“不务正业”,脱离了肉体生存焦虑的回声一代后来者们,在中国商界的地平线上正批量涌现,机器人、跑车、超音速飞机,他们正重写中国创新范式,这一亿多在各行各业走向社会中坚的人群里,一定还会涌现更多、更精彩的创新故事。
最后,梁文锋的一句展望恰可作结:“以后硬核创新会越来越多。现在可能还不容易被理解,是因为整个社会群体需要被事实教育。当这个社会让硬核创新的人功成名就,群体性想法就会改变。我们只是还需要一堆事实和一个过程”。
这一堆事实的展现,已在加速。

本文系观察者网独家稿件,文章内容纯属作者个人观点,不代表平台观点,未经授权,不得转载,否则将追究法律责任。关注观察者网微信guanchacn,每日阅读趣味文章。












