



























DeepSeek,从追赶者到追杀者
本文来自微信公众号:未尽研究 (ID:Weijin_Research),作者:未尽研究,题图来源:视觉中国当美国用户涌入一款便宜、好用的推理大模型后,华尔街对AI的狂热瞬间变为恐慌。一夜之间,英伟达市值跌去6000亿美元,创下美国公司最大单日跌幅历史纪录。DeepSeek从追赶者变成了追杀者,将中国与美国这一轮AI上的差距,从两三年缩短至不足两三个月。硅谷巨头们都感受到了背后越来越近的杀气。应用、大模型与算力的叙事逻辑正在改写。OpenAI难逃“创新者的困境”。就算它每一步都没做错,仍然面临被技术更灵活、价格更低廉的对手颠覆的可能。英伟达证实,DeepSeek使用的GPU完全符合出口标准,否认了ScaleAI的5万张H100的说法。去年圣诞节前,OpenAI刚展示了o3,DeepSeek就在一个月后推出了R1,迅速逼得前者的mini版本免费。奥特曼在社交媒体平台上吹嘘自己刚发布的智能体Operator,底下都是追问DeepSeek的——硅谷的心智正在改变。OpenAI、DeepMind与Anthropic都着力于原始创新阶段,需要基础研发更大比重的支出,早期的持续探索和反复试错,失败率很高。追赶者则享受着算力通缩、路径复现的红利。但是,算力是资源,也就带有资源的诅咒。OpenAl已经习惯于堆叠算力的“暴力美学”,正式发布下一代基础模型一再延期,已经让市场陷入焦虑。DeepSeek无限逼近,让开源模型和闭源模型一样好,并且效率还更高,让更多企业可以用少于以往十分之一的成本构筑应用,给了创新者越来越大的商品化压力。一般来说,创新者以更高的成本,获得技术的先发优势,就会推出差异性的产品,在一段时间内获得市场垄断优势,以补偿其创新的成本并获得超额利润。但AI领域激烈的竞争,追赶者快速逼近甚至实现反超,把领先的创新者逼入越来越短的时间与越来越窄的空间,它们很快被追赶者替代,付出的十倍于追赶者的成本最终可能无法挽回地沉没。用户声称正在无缝切换至DeepSeek的移动应用;AMD已经把DeepSeek-V3集成到MI300X上;Perplexity也将DeepSeek-R1引入了搜索。但DeepSeek只是证明了另一条途径是可行的,并没有否认OpenAl的路径不再会量变引发新的质变。算力长期以来都是硅谷创新“苦涩的教训”。无论是OpenAI,还是DeepSeek,大概率手中还握有更大的底牌。DeepSeek昨晚趁势开源了多模态的Janus-Pro,击败了OpenAI的DALL-E 3和Stable Diffusion,又逼了OpenAI一把。DeepSeek在2025年的第一个月,以一种颠覆性的方式为行业定义了全年的重要创新方向。推理模型的竞争已经提前打响,推理侧的训练和计算,以及更集约的算法,正在重新定义下一代大模型。DeepSeek的创新,是中国创新的写照。它采用的混合专家模型(MoE)、多头潜注意力(MLA)、多令牌预测(MTP)、长链式推理(CoT)、DualPipe算法等设计;依赖强化学习(RL)而不加入监督微调(SFT)的训练尝试;在数据精度(FP8混合精度)、底层通信等方面优化,都不是从0到1的创新。但DeepSeek通过这些技术重新组合、进化,形成了一整套从底层创新到最终产品的“中间技术”。DeepSeek的成功,为中国企业在算力约束下开辟自己的技术路线定下了基调。蒸馏可以走很长的路,纯粹的强化学习也正在重新吸引研究者。分布广泛的高质量数据、相对轻量的推理模型、丰富的实体经济场景,都更有利于中国产业+AI的创新。AI企业创新和应用,将出现中国范式。中国企业在AI的全球扩散中将发挥更重要的作用,中国的AI行业的创新价值,也值得在今年重估。在算力储备富裕的情况下,开源的更集约的探索路线,也意味着更为多元的发散的创新。美国高校与研究者已经将DeepSeek视为新的研究对象。向更高效的路线投入更多算力,意味着抬高了原以为即将触及的天花板,还有可能把下一代模型的能力,再往上提升一个数量级。在这个意义上,中国也仍将追求更强大的算力硬件的自主。苹果是昨晚少数市值收涨的美国科技巨头。更小的参数规模,更低精度的推理,显著降低了算力与内存需求,使得端侧推理更加可行;而苹果拥有最好的硬件,最完善的应用生态,并对引入大模型服务持开放态度。其他美国巨头将不得不应对来自中国的价格战。杰文斯悖论将主导下一阶段的AI叙事。尽管在短期内,DeepSeek的效率和广泛可用性,给英伟达最乐观的增长前景带来了严重的质疑,但英特尔前CEO基辛格、微软CEO纳德拉,都重提了英国工业革命期间的经济学家杰文斯的发现:当煤炭的使用效率不断提升时,对煤炭的需求不仅没有下降,反而在煤炭的应用和相关领域产生了大量的创新,渗透到各行各业,导致煤炭的消耗量上升。杰斯悖论在能源电力领域得到了完全的验证,长期来看,在AI与算力领域也将重演。在加速计算逐步占据主流的深度学习“黄金10年”,GPU的效率提升了千倍。但智能算力的需求在绝对数量和相对占比的意义上,不但没有减少,反而在加速增长,每个季度翻番。在DeepSeek之前,它是训练需求推动的,大型智算集群不断涌现;之后,将是推理需求推动的,海量应用即将涌现。如果考虑到未来的物理AI,世界对于算力的需求几乎是无限的。从长期来自,DeepSeek的创新,正是推动了AI计算成本的下降,每秒处理更多的tokens,单位成本、单位能耗能产生更多的Flops;它降低了AI技术门槛,会加快AI应用的涌现,也会让更多的行业采纳AI。但算力长期增长的市场逻辑,不一定能支撑着芯片企业中短期内的估值逻辑。英伟达从去年底开始就面临前所未有的竞争威胁,当前股价暗示的增长轨迹不断承压,终于在DeepSeek冲击下,市场开始抛售这种不确定性。当市场利润的大部分从流入芯片转向流入应用,供需关系的逆转也将反映在利润率之上。这是AI创新进入应用阶段的标志性事件。每个人都在接受这样一种观念:一场全球竞赛正在发生,我们不能输掉它。在地缘竞争的催化下,DeepSeek在美国的硅谷与华尔街引发强震,余震也已经传导至华盛顿。上周,达沃斯论坛的共识是,美国在人工智能全球竞争上的最大问题是,是否有足够的承包商来建设高达5000亿美元的星际之门计划这样庞大的项目;今天,特朗普在佛罗里达州说,DeepSeek带来的变化是积极的,为美国敲响了警钟,需要专注于竞争以赢得胜利。
本文来自微信公众号:未尽研究 (ID:Weijin_Research),作者:未尽研究,题图来源:视觉中国
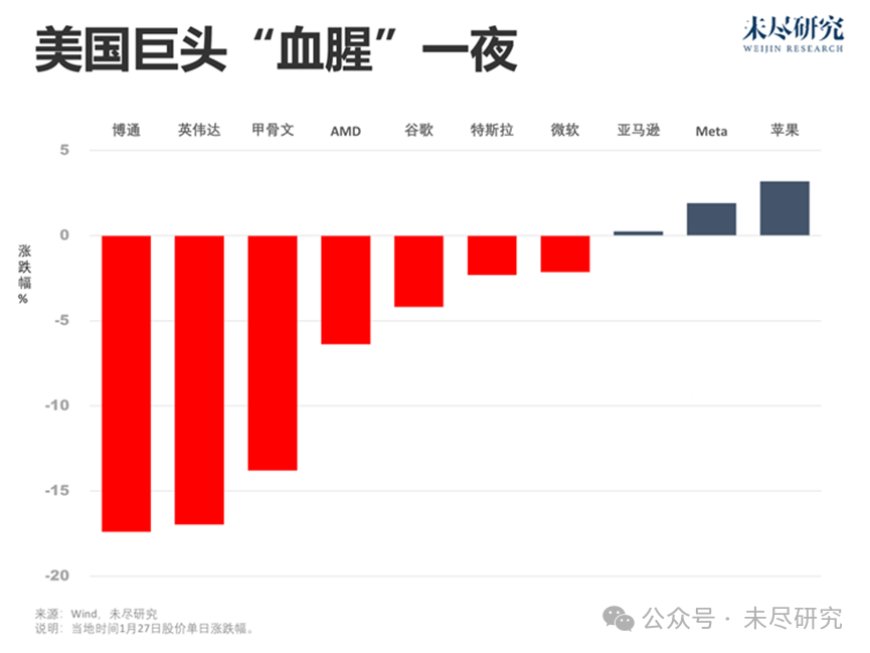
当美国用户涌入一款便宜、好用的推理大模型后,华尔街对AI的狂热瞬间变为恐慌。一夜之间,英伟达市值跌去6000亿美元,创下美国公司最大单日跌幅历史纪录。

DeepSeek从追赶者变成了追杀者,将中国与美国这一轮AI上的差距,从两三年缩短至不足两三个月。硅谷巨头们都感受到了背后越来越近的杀气。应用、大模型与算力的叙事逻辑正在改写。
OpenAI难逃“创新者的困境”。就算它每一步都没做错,仍然面临被技术更灵活、价格更低廉的对手颠覆的可能。英伟达证实,DeepSeek使用的GPU完全符合出口标准,否认了ScaleAI的5万张H100的说法。
去年圣诞节前,OpenAI刚展示了o3,DeepSeek就在一个月后推出了R1,迅速逼得前者的mini版本免费。奥特曼在社交媒体平台上吹嘘自己刚发布的智能体Operator,底下都是追问DeepSeek的——硅谷的心智正在改变。
OpenAI、DeepMind与Anthropic都着力于原始创新阶段,需要基础研发更大比重的支出,早期的持续探索和反复试错,失败率很高。追赶者则享受着算力通缩、路径复现的红利。但是,算力是资源,也就带有资源的诅咒。OpenAl已经习惯于堆叠算力的“暴力美学”,正式发布下一代基础模型一再延期,已经让市场陷入焦虑。
DeepSeek无限逼近,让开源模型和闭源模型一样好,并且效率还更高,让更多企业可以用少于以往十分之一的成本构筑应用,给了创新者越来越大的商品化压力。
一般来说,创新者以更高的成本,获得技术的先发优势,就会推出差异性的产品,在一段时间内获得市场垄断优势,以补偿其创新的成本并获得超额利润。但AI领域激烈的竞争,追赶者快速逼近甚至实现反超,把领先的创新者逼入越来越短的时间与越来越窄的空间,它们很快被追赶者替代,付出的十倍于追赶者的成本最终可能无法挽回地沉没。
用户声称正在无缝切换至DeepSeek的移动应用;AMD已经把DeepSeek-V3集成到MI300X上;Perplexity也将DeepSeek-R1引入了搜索。
但DeepSeek只是证明了另一条途径是可行的,并没有否认OpenAl的路径不再会量变引发新的质变。算力长期以来都是硅谷创新“苦涩的教训”。无论是OpenAI,还是DeepSeek,大概率手中还握有更大的底牌。DeepSeek昨晚趁势开源了多模态的Janus-Pro,击败了OpenAI的DALL-E 3和Stable Diffusion,又逼了OpenAI一把。
DeepSeek在2025年的第一个月,以一种颠覆性的方式为行业定义了全年的重要创新方向。推理模型的竞争已经提前打响,推理侧的训练和计算,以及更集约的算法,正在重新定义下一代大模型。
DeepSeek的创新,是中国创新的写照。它采用的混合专家模型(MoE)、多头潜注意力(MLA)、多令牌预测(MTP)、长链式推理(CoT)、DualPipe算法等设计;依赖强化学习(RL)而不加入监督微调(SFT)的训练尝试;在数据精度(FP8混合精度)、底层通信等方面优化,都不是从0到1的创新。但DeepSeek通过这些技术重新组合、进化,形成了一整套从底层创新到最终产品的“中间技术”。
DeepSeek的成功,为中国企业在算力约束下开辟自己的技术路线定下了基调。蒸馏可以走很长的路,纯粹的强化学习也正在重新吸引研究者。分布广泛的高质量数据、相对轻量的推理模型、丰富的实体经济场景,都更有利于中国产业+AI的创新。AI企业创新和应用,将出现中国范式。中国企业在AI的全球扩散中将发挥更重要的作用,中国的AI行业的创新价值,也值得在今年重估。
在算力储备富裕的情况下,开源的更集约的探索路线,也意味着更为多元的发散的创新。美国高校与研究者已经将DeepSeek视为新的研究对象。向更高效的路线投入更多算力,意味着抬高了原以为即将触及的天花板,还有可能把下一代模型的能力,再往上提升一个数量级。在这个意义上,中国也仍将追求更强大的算力硬件的自主。
苹果是昨晚少数市值收涨的美国科技巨头。更小的参数规模,更低精度的推理,显著降低了算力与内存需求,使得端侧推理更加可行;而苹果拥有最好的硬件,最完善的应用生态,并对引入大模型服务持开放态度。其他美国巨头将不得不应对来自中国的价格战。
杰文斯悖论将主导下一阶段的AI叙事。尽管在短期内,DeepSeek的效率和广泛可用性,给英伟达最乐观的增长前景带来了严重的质疑,但英特尔前CEO基辛格、微软CEO纳德拉,都重提了英国工业革命期间的经济学家杰文斯的发现:当煤炭的使用效率不断提升时,对煤炭的需求不仅没有下降,反而在煤炭的应用和相关领域产生了大量的创新,渗透到各行各业,导致煤炭的消耗量上升。杰斯悖论在能源电力领域得到了完全的验证,长期来看,在AI与算力领域也将重演。

在加速计算逐步占据主流的深度学习“黄金10年”,GPU的效率提升了千倍。但智能算力的需求在绝对数量和相对占比的意义上,不但没有减少,反而在加速增长,每个季度翻番。在DeepSeek之前,它是训练需求推动的,大型智算集群不断涌现;之后,将是推理需求推动的,海量应用即将涌现。如果考虑到未来的物理AI,世界对于算力的需求几乎是无限的。
从长期来自,DeepSeek的创新,正是推动了AI计算成本的下降,每秒处理更多的tokens,单位成本、单位能耗能产生更多的Flops;它降低了AI技术门槛,会加快AI应用的涌现,也会让更多的行业采纳AI。
但算力长期增长的市场逻辑,不一定能支撑着芯片企业中短期内的估值逻辑。英伟达从去年底开始就面临前所未有的竞争威胁,当前股价暗示的增长轨迹不断承压,终于在DeepSeek冲击下,市场开始抛售这种不确定性。当市场利润的大部分从流入芯片转向流入应用,供需关系的逆转也将反映在利润率之上。这是AI创新进入应用阶段的标志性事件。
每个人都在接受这样一种观念:一场全球竞赛正在发生,我们不能输掉它。在地缘竞争的催化下,DeepSeek在美国的硅谷与华尔街引发强震,余震也已经传导至华盛顿。
上周,达沃斯论坛的共识是,美国在人工智能全球竞争上的最大问题是,是否有足够的承包商来建设高达5000亿美元的星际之门计划这样庞大的项目;今天,特朗普在佛罗里达州说,DeepSeek带来的变化是积极的,为美国敲响了警钟,需要专注于竞争以赢得胜利。












