



























刚刚,OpenAI 重磅发布 o3!再次突破 AI 极限,北大校友参与研发
o3 模型终于来了。#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。 爱范儿 | 原文链接 · 查看评论 · 新浪微博


就在刚刚,OpenAI 迎来了年底 AI 春晚的收官之作。
这次发布的的 o3 系列模型是 o1 的迭代版本,考虑到可能与英国电信运营商 O2 存在版权或商标冲突,OpenAI 决定跳过「o2」命名,直接采用「o3」。
为此,OpenAI CEO Sam Altman 更是自嘲公司在模型命名方面的混乱,原来你也知道呀。
本次发布会由 Sam Altman、研究高级副总裁 Mark Chen 以及研究科学家 Hongyu Ren(任泓宇)主持。

值得注意的是,任泓宇本科毕业于北大,对 o1 有过基础性贡献,也是 GPT-4o 的核心开发者,曾在苹果、微软和英伟达有过丰富的研究实习经历。
o3 系列包含两款重磅模型:
- OpenAI o3:旗舰版本,具备强大的性能表现
- OpenAI o3 mini:轻量级模型,但能更快,更便宜,主打性价比
先别急着高兴,因为 o3 系列目前并不会向普通用户开放,OpenAI 计划先开放外部安全测试申请,正式发布时间预计要到明年 1 月。
现在,感兴趣的朋友可以提交申请:
https://openai.com/index/early-access-for-safety-testing/
o3 性能大跃迁,死记硬背?不存在的
o3 模型的「纸面参数」迎来了全方位提升。
首先在 SweepBench Verified 基准测试中, o3 达到了约 71.7% 的准确率,直接将 o1 模型甩在身后整整 20% 之多。
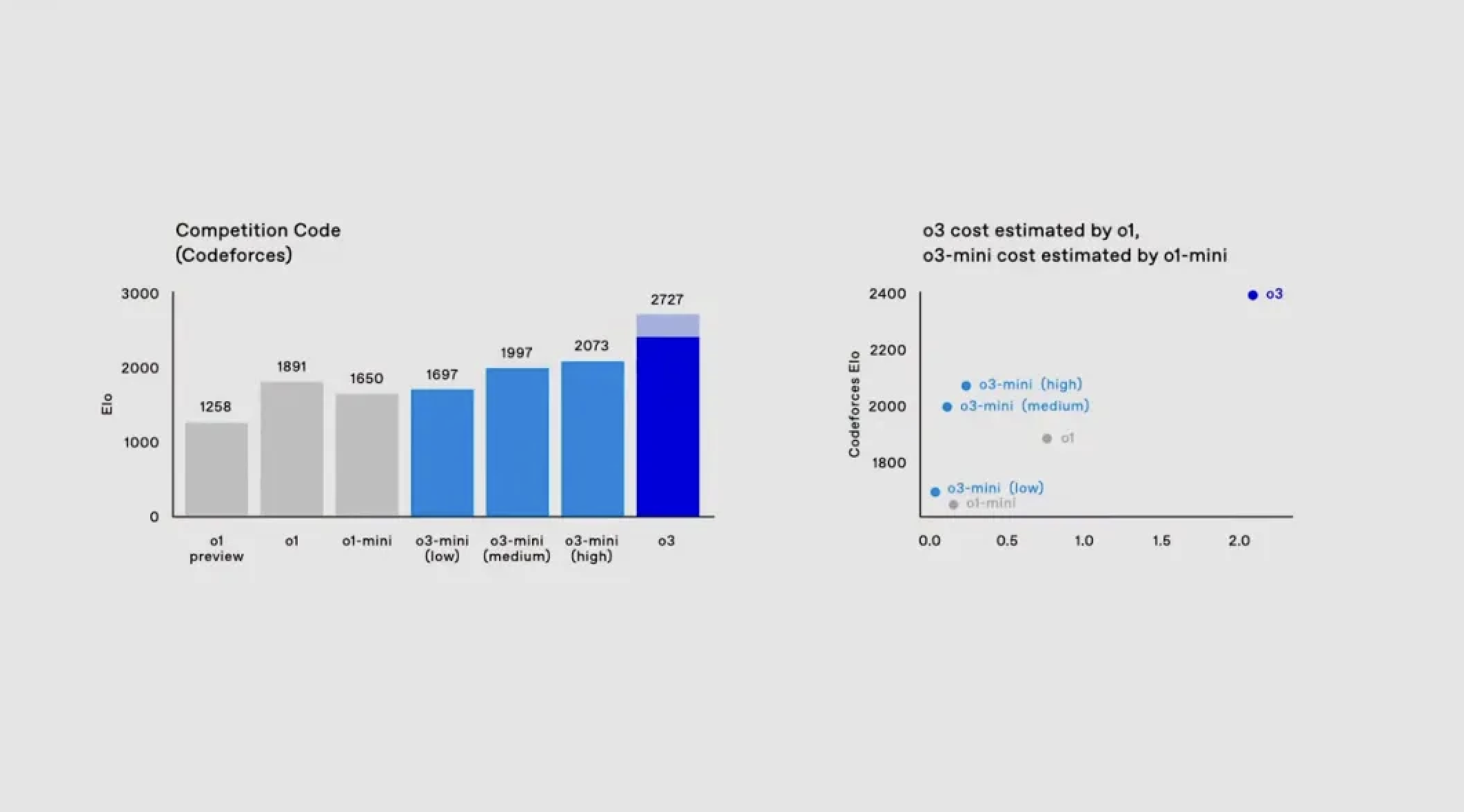
转入编码领域,o1 在编程竞赛平台 Codeforces 上的得分为 1891。而 o3 在开足马力,延长思考时间的情况下,得分可达 2727。
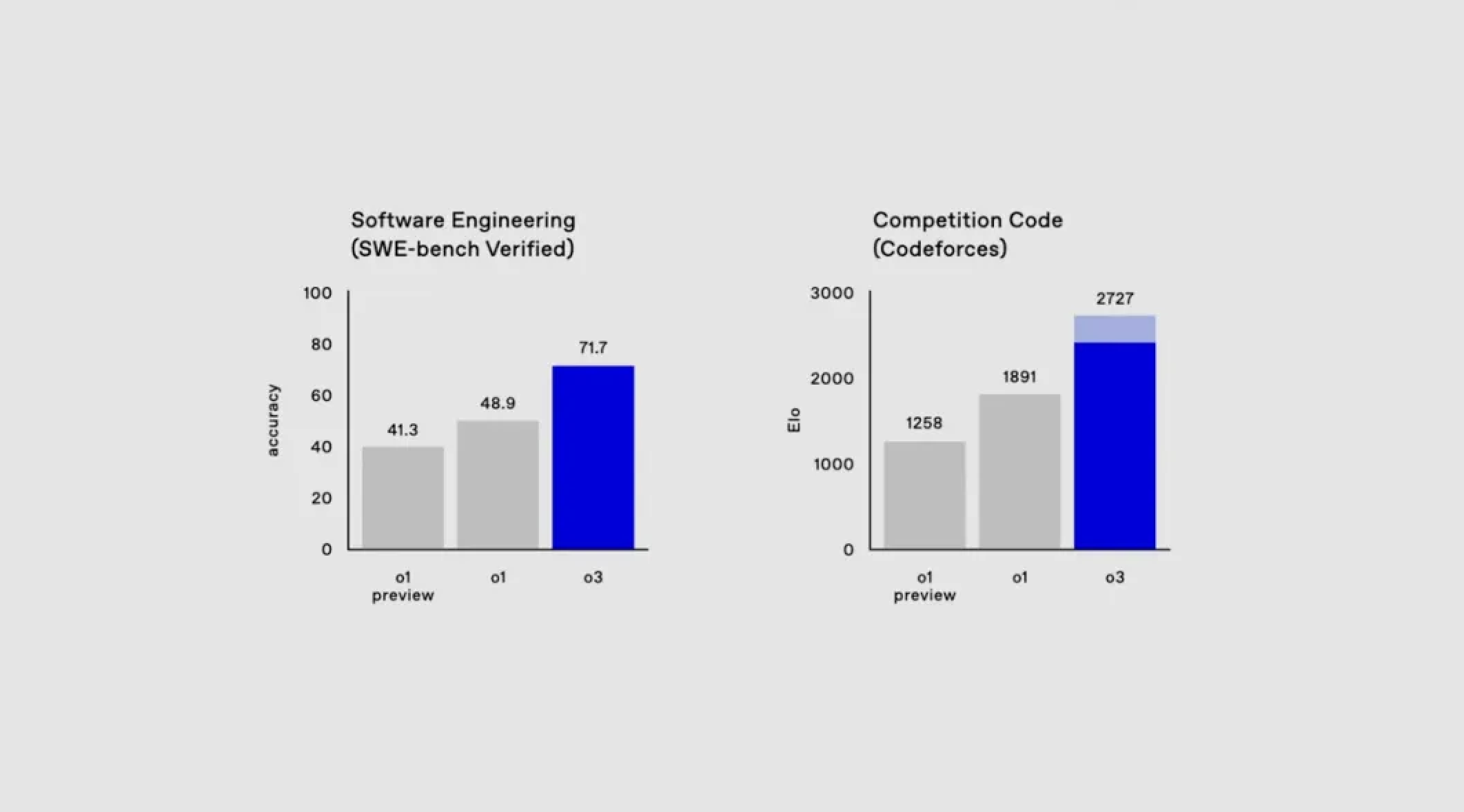
作为参照,演示人员 Mark Chen 的得分也只有 2500,充分展现了 o3 模型已经具备接近甚至超越人类专业程序员的实力。
在数学领域,o3 同样表现出色。
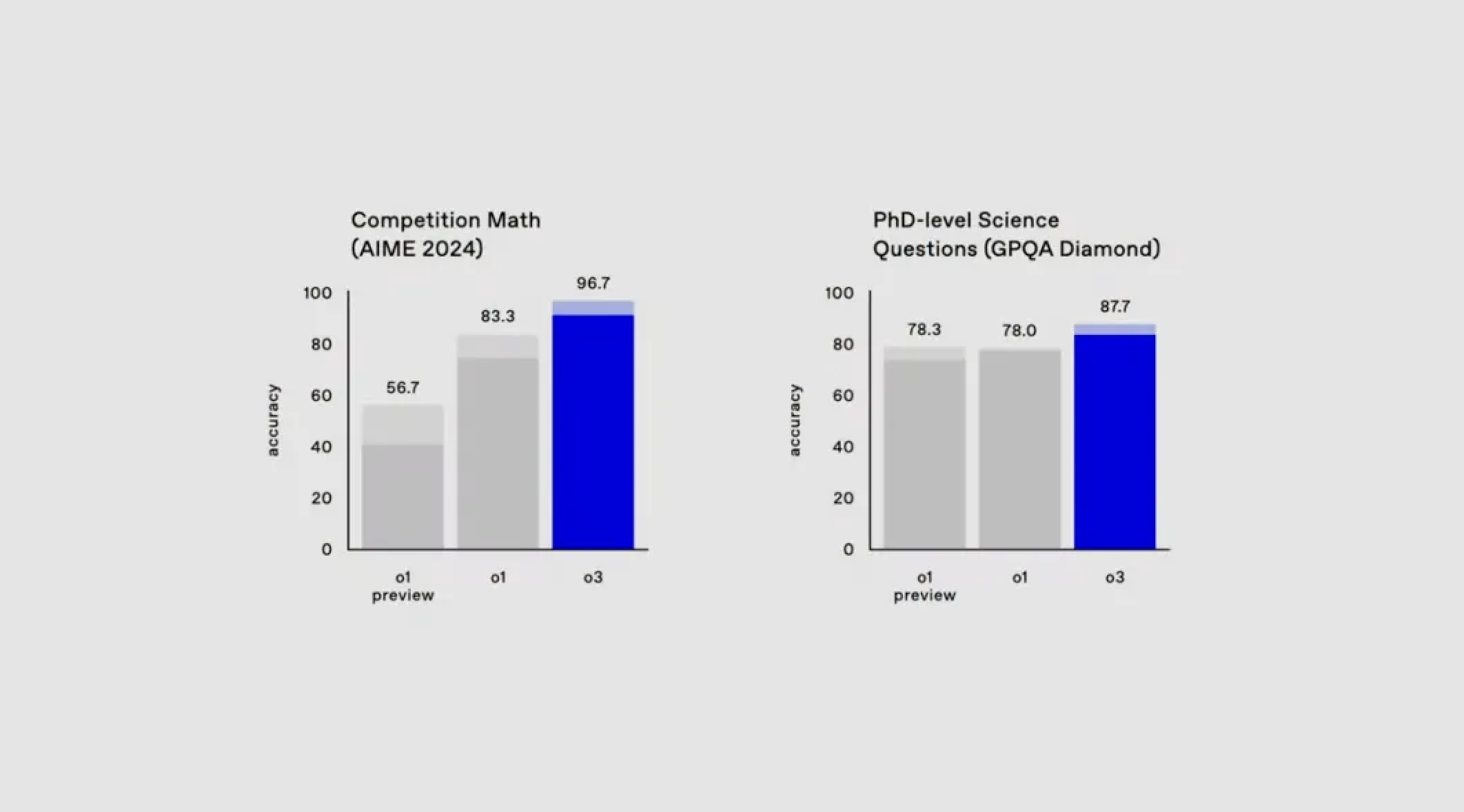
在美国数学竞赛 AIME 2024 测试中,o3 以 90.67% 的准确率完全碾压了 o1 的 83.3%。
遇上衡量博士级科学问题解答能力的 GPQA Diamond 测试,o3 取得了 87.7% 的成绩,而 o1 仅为 78%。
什么概念呢?要知道,就算是领域内的博士专家,也往往只能在自己的专业范围内达到约 70% 的准确率。
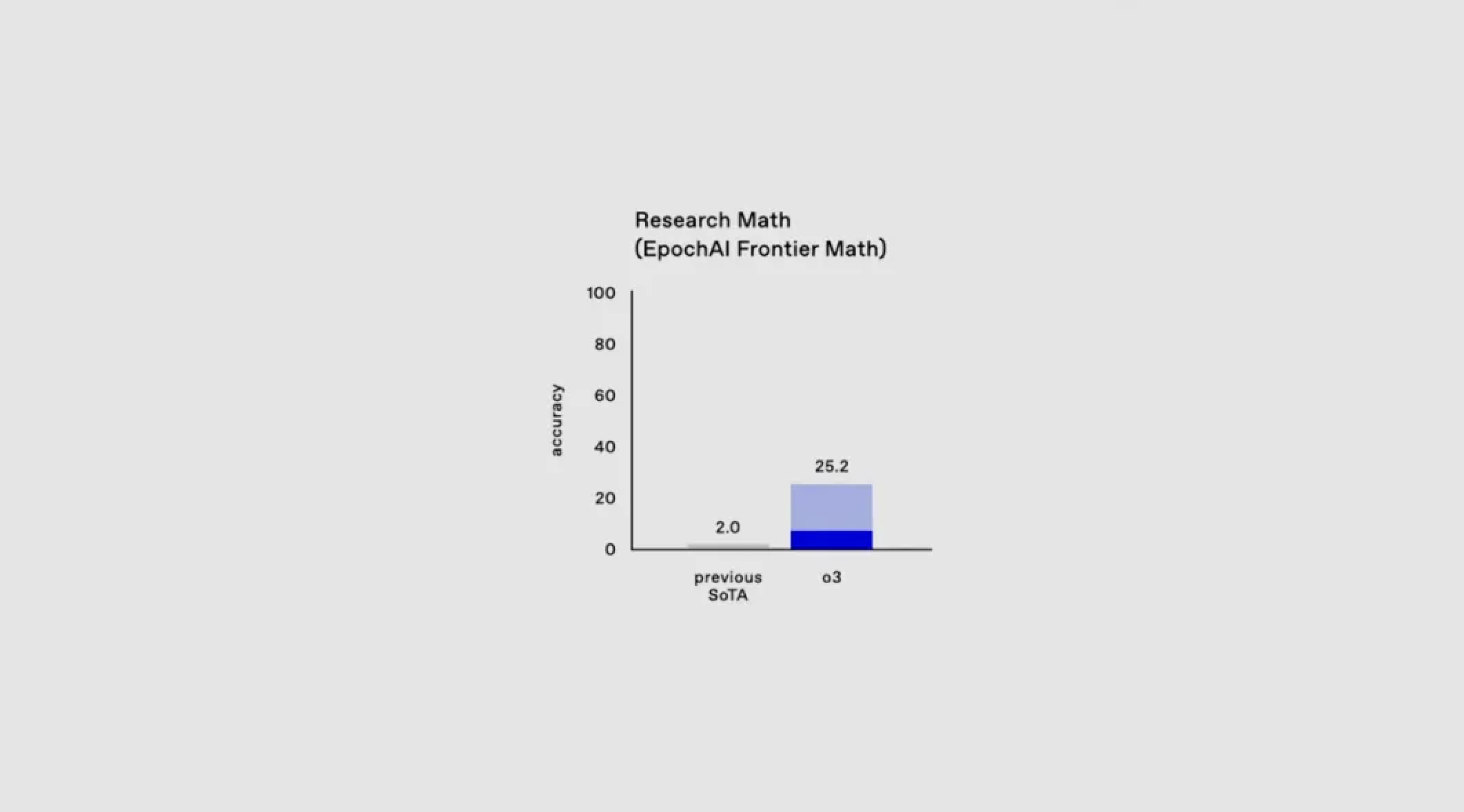
面对当前基准测试接近满分的情况,OpenAI 引入了一个全新的数学测试 EpochAI Frontier Math。
这被认为是当前最具挑战性的数学评估之一,包含了极其复杂的问题。就连专业数学家解决单个问题也需要耗费数小时甚至数天。
目前,所有现有模型在该测试上的准确率都不足 2%,而在高算力的长时间测试下,o3 却能取得超过 2457 的分数。
说到 AI 领域的圣杯 AGI,也就不得不提到 ARC-AGI 这个专门衡量 AGI 的基准测试。
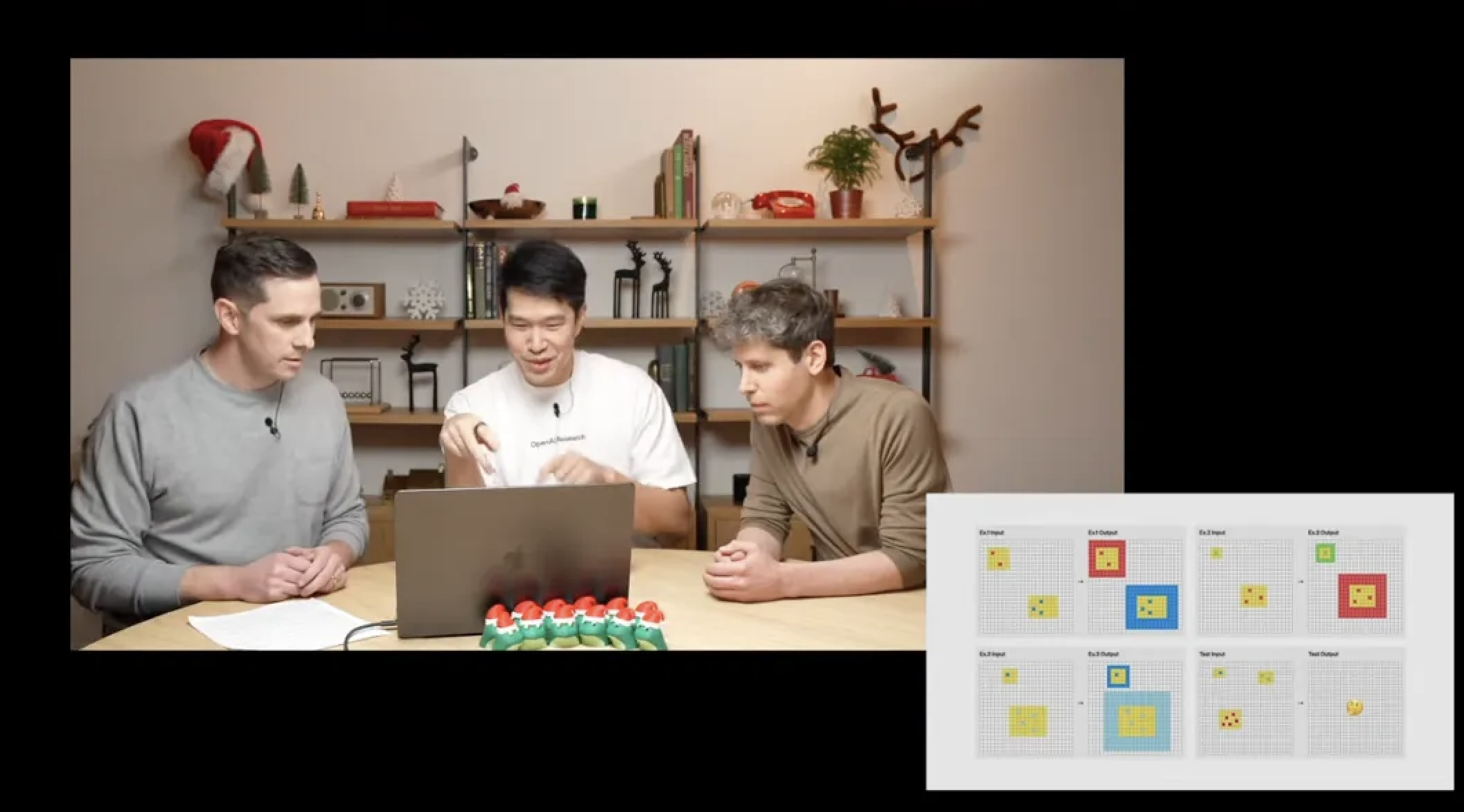
ARC-AGI 是由 Keras 之父 François Chollet 开发,主要是通过图形逻辑推理来测试模型的推理能力。

当演示人员向另一位演示人员 Mark Chen 提出即兴问题时,后者准确指出了任务的要求:需要计算每个黄色方块中彩色小方块的数量,并据此生成相应的边框。
这些对人类来说再简单不过的任务,对 AI 来说却是一道难题。
并且,ARC-AGI 的每个任务都需要不同的技能,且刻意避免重复,完全杜绝了模型靠「死记硬背」取巧的可能,真正测试模型实时学习和应用新技能的能力。
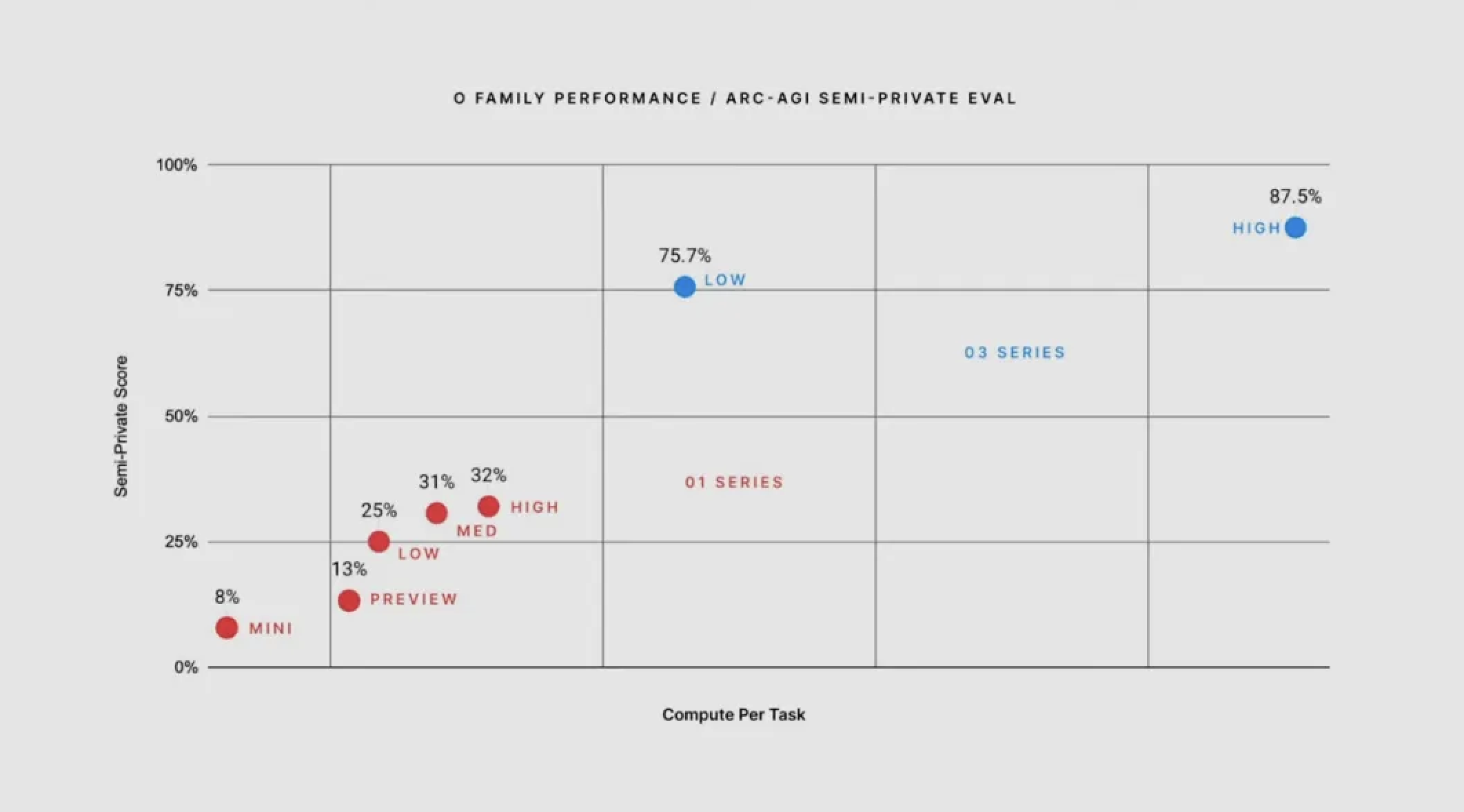
现在,o3 在低算力的配置下得分 75.7 分。当要求 o3 思考更长时间,并且提高算力,o3 在相同的隐藏保留集上得分 87.5%,远超大多数真人。
OpenAI 的言外之意就是,o3 将让我们离 AGI 更近一步。
o3 mini 重磅发布,速度更快,成本更低
今年九月,OpenAI 发布了 o1 mini,具有很强的数学和编程能力,而且成本极低。
延续这一发展方向,今天推出的 o3 mini 也保留了上述特征。即日起,该模型仅向安全研究人员开放测试申请,截止日期为 1 月 10 日。
o3 mini 支持低、中、高三种推理时间模式。
用户可根据任务复杂度灵活调整模型的思考时间。例如,复杂问题可选择更长的思考时间,而简单问题则可快速处理。
从首批评估结果来看,在衡量编程能力的 Codeforces Elo 评分中,随着推理时间的增加,其 Elo 分数持续攀升,在中等推理时间下就已超越 o1 mini。
演示人员要求模型使用 Python 创建了一个代码生成器和执行器,该脚本可启动服务器并创建本地用户界面。用户可在文本框中输入代码请求,系统会将请求发送至三种高级模式的 API,生成并执行相应代码。
例如,当要求其生成一个包含 OpenAI 和随机数的代码时,o3 mini 的中等推理模式迅速完成了处理。
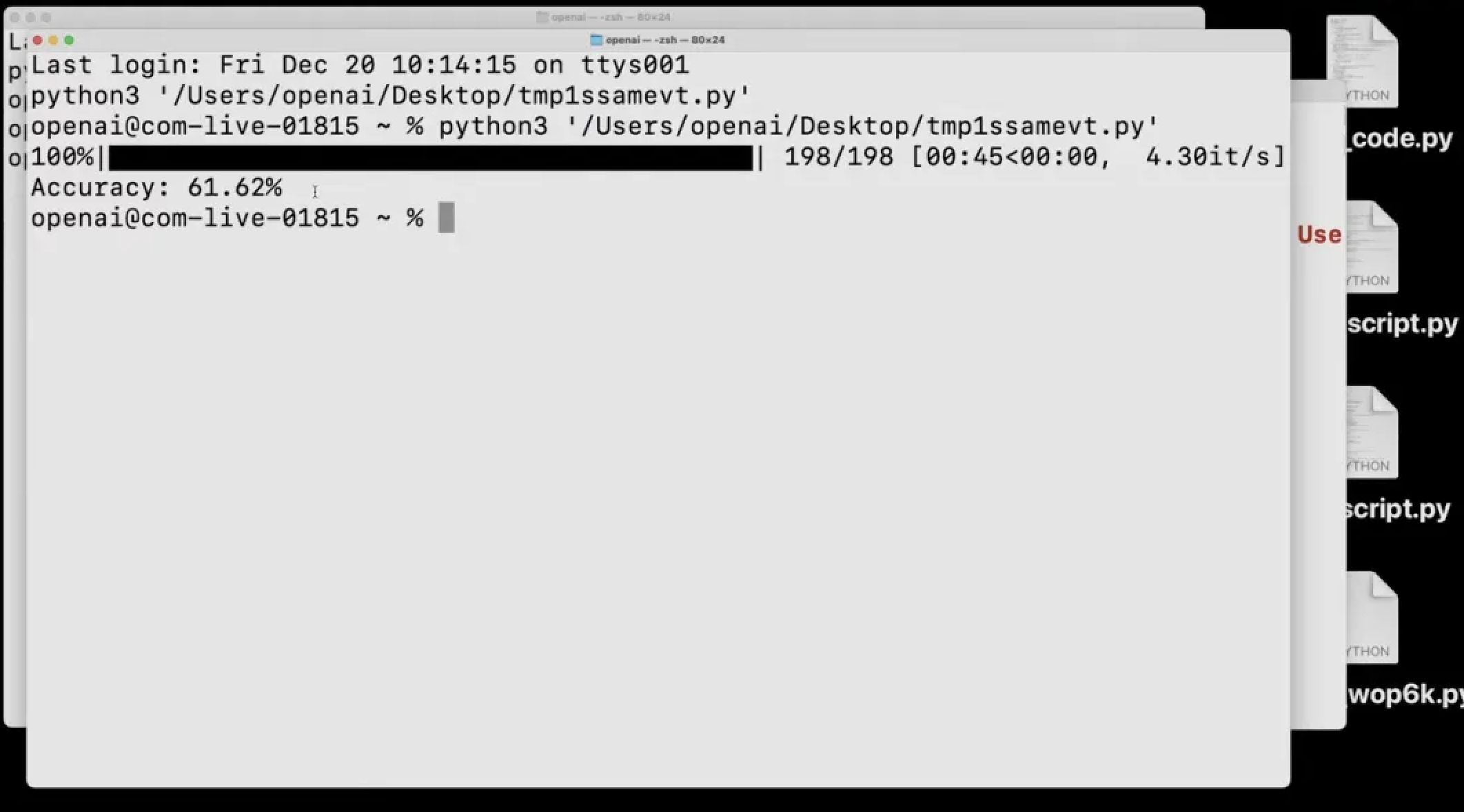
另外,它还能自己测试自己,比如说在 GPQA 数据集测试中,模型以低推理模式完成了复杂数据集的评估。
它下载原始文件,识别 CSS、答案和选项,整理问题并进行解答,最后进行评分,仅用一分钟就完成了自我评估,准确率达到 61.62%。
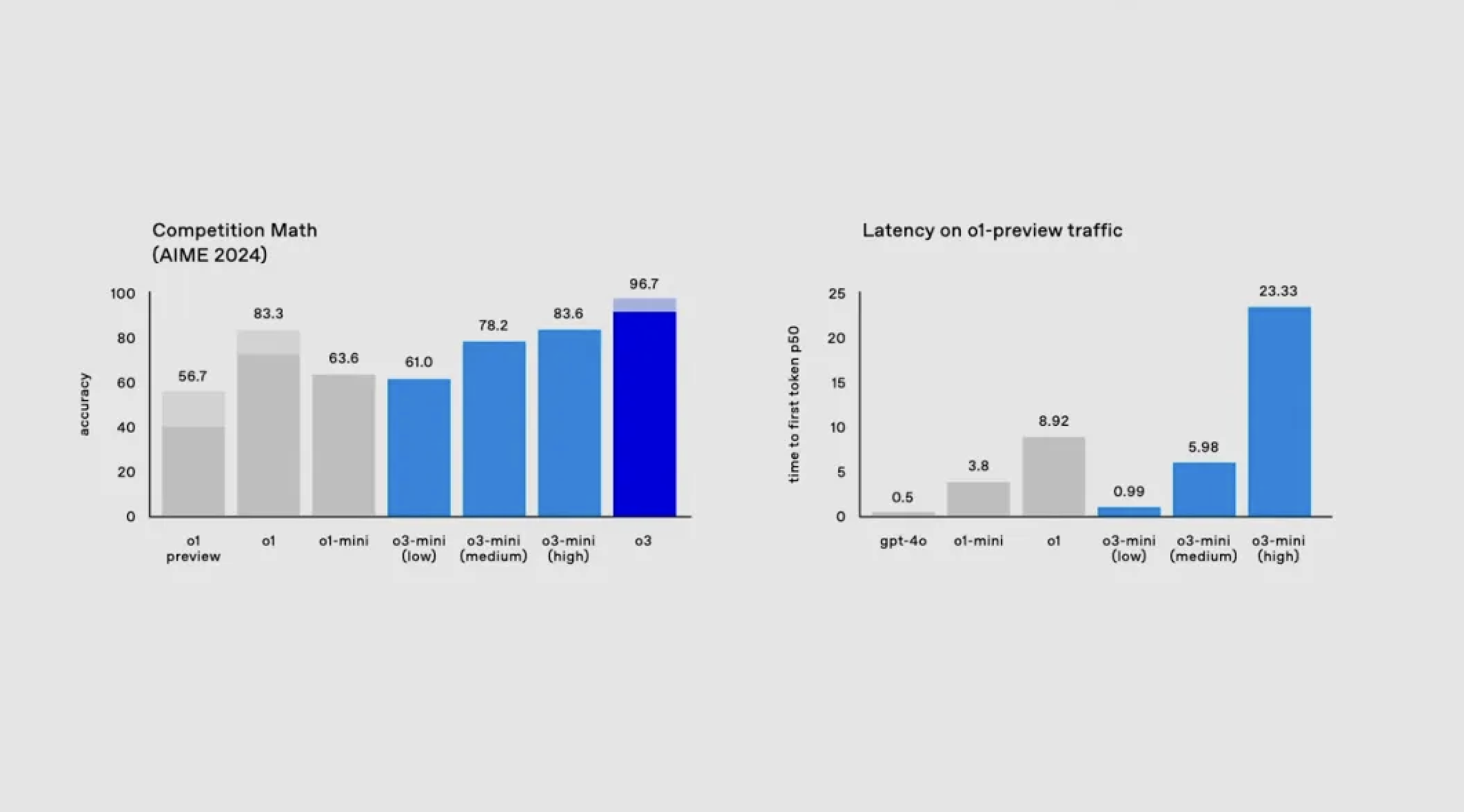
在数学领域,o3 mini 同样表现优秀。
在 AIME 数学基准测试中,其低推理模式就达到了与 o1 mini 相当的性能,中等推理模式更是超越了 o1 mini,且延时更低。
另外,应广大开发者呼声,o3 mini 模型也将全面支持函数调用、结构化输出和开发者指令等 API 功能。
现在,o3 mini 和 o3 的申请通道现已开放。o3 mini 预计将于 1 月向所有用户推出,完整版 o3 则将在后续发布。
写在最后,在这个为期 12 天的年末发布会上,OpenAI 终于祭出了压箱底的杀手锏。
可以说,o3 模型的发布为这场一度陷入「高开低走」困境的发布会,画上了一个意料之外却又情理之中的圆满句号。
短短不到 3 个月的时间,OpenAI 就完成了 o1 模型的迭代升级。
这种从 GPT 系列到 o 系列的转型,显然是 OpenAI 深思熟虑后的战略选择,而事后结果也证明这个决定是明智的。

不过,值得注意的是,微软 CEO Satya Nadella 近期在一档播客节目中表示,OpenAI 在 AI 领域领先竞争对手约两年之久。
也正是这种相对宽松的竞争环境,使得 OpenAI 能够专注于开发 ChatGPT。
然而,当前形势攻守易形也。
Menlo Ventures 的报告显示,ChatGPT 的市场份额被其他竞争对手逐渐蚕食,从 2023 年的 50% 下降到了 2024 年的 34%。
由「标配」沦为「可选项」,ChatGPT 的光环正在褪去。
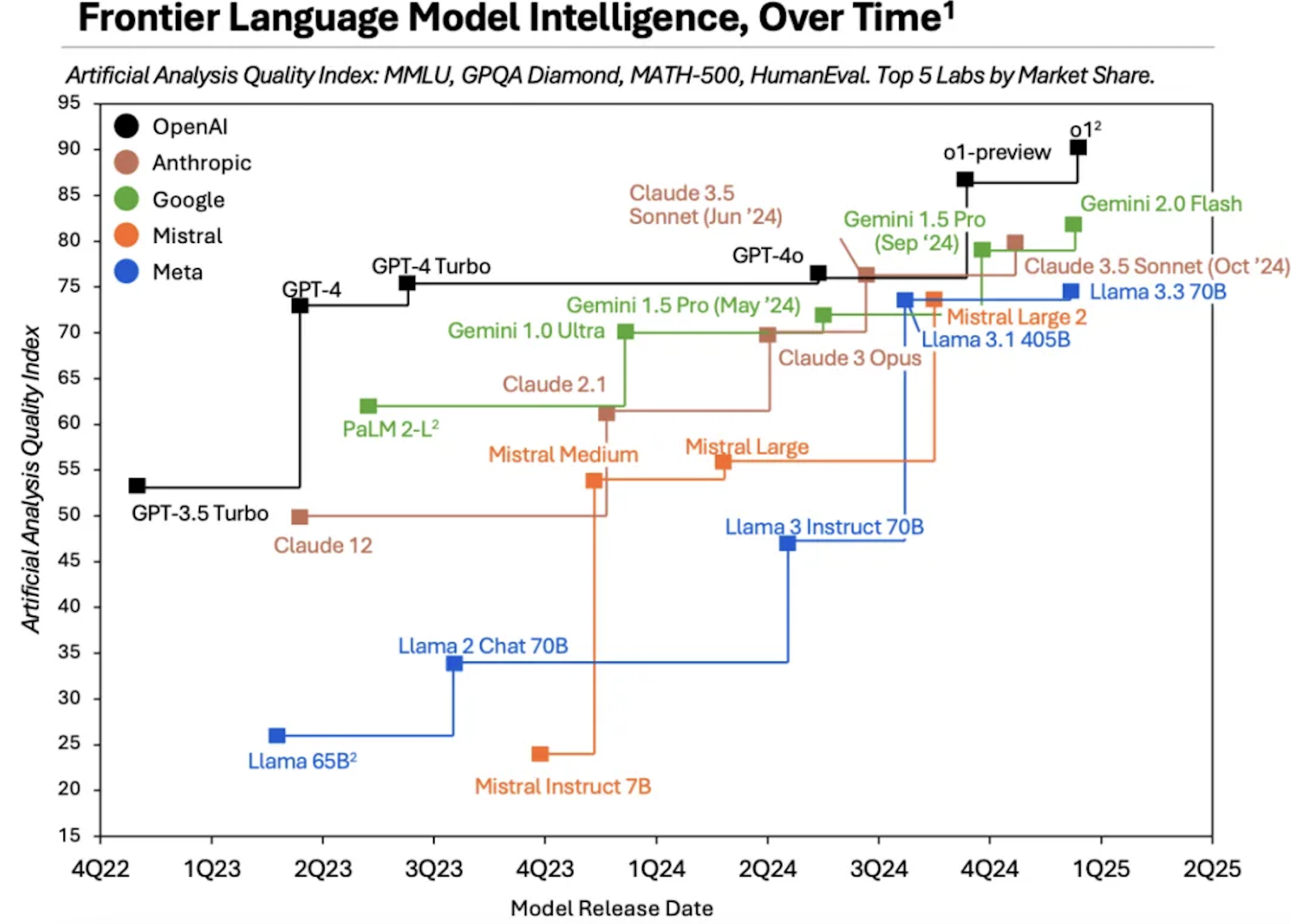
这背后的原因显而易见,OpenAI 的「护城河」正被短命狂奔的竞争对手们一寸寸填平。
来自 Artificial Analysis 的调研数据清晰显示,Anthropic 和 Google 等厂商陆续开发出性能接近 GPT-4、OpenAI o1 等新模型。
并且,随着 Scaling Law 触及天花板,核心高管人才相继离场,OpenAI 过往靠单个基础模型赢得的红利正在加速消退。

在动辄以天计的行业里,即便是今日发布的 o3 模型也很难再次创造长达 2 年的空窗期。
尤其是当 Grok-3 和 Claude 等新模型蓄势待发,留给 OpenAI 的时间或许已经不多了。
醒醒,今年最好的 AI 厂商依旧是 OpenAI,但明年或许会因为不同的 AI 方向有无数种答案。
所幸,作为用户的我们,都将是这场变局中最大的赢家。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。












