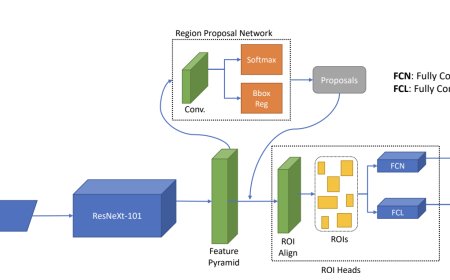
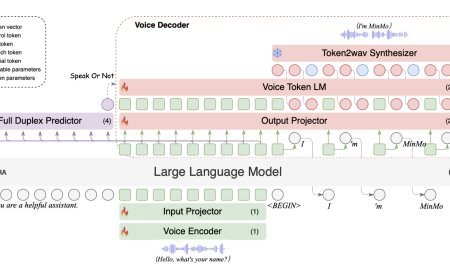
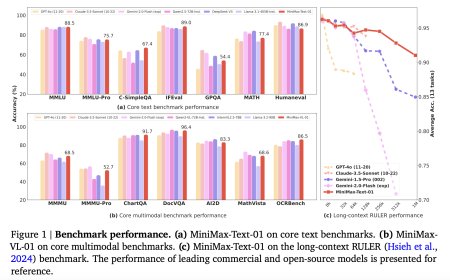
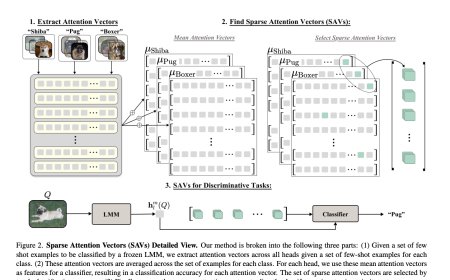































FACTS Grounding: A new benchmark for evaluating the factuality of large language models
Our comprehensive benchmark and online leaderboard offer a much-needed measure of how accurately LLMs ground their responses in provided source material and avoid hallucinations
Our comprehensive benchmark and online leaderboard offer a much-needed measure of how accurately LLMs ground their responses in provided source material and avoid hallucinations












